CPU缓存架构到内存屏障
文章目录
CPU缓存架构
现代处理器一般是多核架构,并且为了平衡CPU和内存的速度差距,还引入了多级Cache,Cache的读写速度介于CPU寄存器和内存之间。

CPU Cache 是由很多个 Cache Line 组成,每个Cache Line大小为64B。Cache Line 是 CPU从内存读写数据的基本单位,每次从内存中读取完整的一个Cache Line到Cache进行读写操作(空间局部性原理)。
我们期望 CPU 读取数据时,都是尽可能地从CPU Cache中读取,⽽不是每⼀次都要从内存中获取数据;数据写⼊ Cache 之后,Cache与内存相对应的数据将会不同(dirty),需要把Cache中的数据同步到内存⾥的。
Cache Line从Cache写回内存由两种方案:
- 写直达 Writer Through,把数据同时写入内存和Cache中;性能较差
- 写回 Writer Back,新的数据仅仅被写⼊Cache⾥,只有当修改过的Cache Line被换出时才需要写到内存中,减少数据写回内存的频率;性能较好
实际上,在CPU和L1 Cache之间还存在Store Buffer,也会用于缓存Cache Line,它的作用和影响在下面介绍。
Cache的引入缓解了内存访问的延迟问题,但也带来了Cache一致性的问题:
当多个核心同时加载同一个Cache Line到Cache时,如果其中一个核心对Cache Line中的数据做了修改,另外一个CPU并不能察觉,还在使用旧的值进行操作,不同核心的Cache数据就会出现不一致。
Cache一致性 Cache Coherence
多级缓存的引入带来不同CPU核心上的本地Cache之间的一致性问题,称为Cache一致性Cache coherence问题。
MESI协议
多核CPU使用总线进行通信,可以基于总线通信实现Cache的强一致性。目前使用较多的是MESI协议或一些优化协议。
基本思想是:
- 当只有CPU0从内存加载某个Cache Line到Cache时,这个Cache Line是Exclusive状态;
- 当这个Cache Line又被CPU1加载,更改状态为Shared;
- 这时CPU0要修改Cachel Line中的某个变量, 就把状态改为Modified,并且Invalidate其他Cache中的这个Cache Line,其他的Cache再去获取当前最新状态,达到一致。

Cache Line有4种不同的状态:
- E(独占 Exclusive):缓存行只在当前缓存中,缓存数据和主存相同
- 当别的缓存读取该cache line时,变为共享状态;
- 本地核心写数据时,变为已修改状态。
- S(共享 Shared):缓存行也存在于其它缓存中且都没有进行修改。缓存行可以在任意时刻抛弃。
- 如果要修改,变为已修改状态,并通知其它核心变为Invalid
- M(已修改 Modified):缓存行被修改,与主存的值不同。
- 如果其它核心也持有该行,则其它核心的状态变为无效
- 如果其它核心要读这块数据,该缓存行必须回写到主存同时发给其它读取的核心,状态变为共享(S).
- I(无效Invalid):缓存行是无效的
- 缓存行的初始状态,不在缓存中
- 在缓存中,但内容已过时(被其它核心修改)
核心之间通信需要以下消息机制:
- Read: CPU发起数据读取请求,请求中包含数据的地址
- Read Response: Read消息的响应,该消息有可能是内存响应的,有可能是其他核心响应的
- 如果该地址存在于其他核心的cache line中,且状态为Modified,此时其它核心必须响应最新数据,并将修改刷入主存
- Invalidate: 核心通知其他核心将它们自己核心上对应的cache line置为Invalid
- Invalidate ACK: 其他核心对Invalidate通知的响应,将对应cache line置为Invalid之后发出该确认消息
- Read Invalidate: 相当于Read消息+Invalidate消息,即当前核心要读取数据并修改该数据。
- 会由I状态变为M状态
- Write Back: 写回,将Modified的数据写回到低一级存储中
- 写回会尽可能地推迟内存更新,只有当替换算法要驱逐更新过的块时才写回到低一级存储器中。
MESI协议的状态转移图
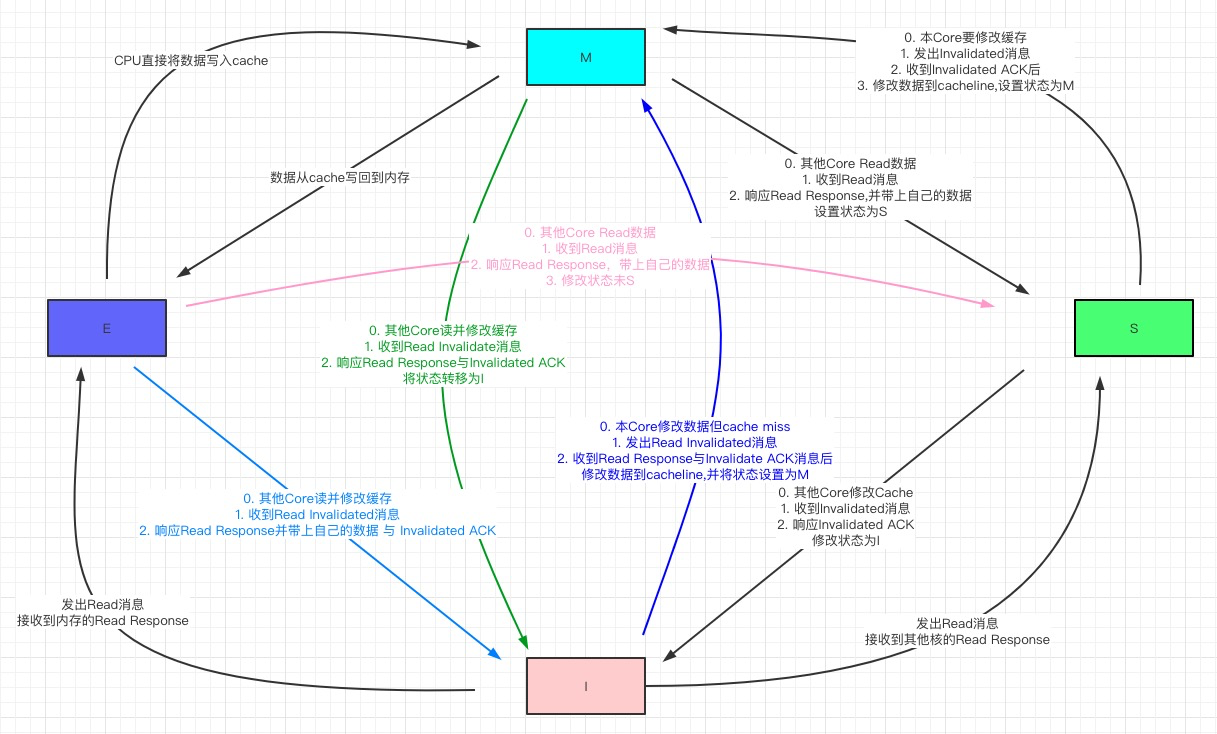
MESI协议解决了多核环境cache多层级带来的一致性问题,CPU核心对本地cache的修改可以被其它核心观测到,使得cache层对于CPU来说是透明的。单一地址变量的写入,可以以线性的逻辑进行理解。
MESI带来的问题
False Sharing
由于CPU以64B的Cache Line为最小单位从内存中加载数据,可能会出现这样的问题:
- 假设变量a和b位于同一个Cache Line中,当前CPU0和CPU1都将这个Cache Line加载到Cache,CPU0只修改变量a,CPU1只读取变量b。
- 当CPU0修改a时,CPU1的Cache Line会变为Invalid状态,即使CPU1并没有修改b,这会导致CPU1从内存或其它核心重新加载Cache Line中的所有变量,影响性能。
这就是False Sharing。
解决False Sharing的常用方法是进行字节填充,在a和b之间填充无意义的变量,使一个变量单独占用一个Cache Line。在Go的源码中经常看到这样的用法,通常在结构体字段之间使用适当长度的字节数组进行填充。
RMW操作不安全
MESI协议无法保证并发场景下RMW操作(Read-Modify-Write操作,如CAS/ADD等需要先读取再计算最后写回)的安全性。
例如两个线程都执行 i++,i的初值为 0。
- 两个核心执行 Read 操作的时候,CPU0 和CPU1的 cache 都是 Shared 状态
- 两个核心各自修改自己的寄存器,然后准备将寄存器值需要写入到 cache
- 假设,CPU1 先完成写入cache的操作,状态变为Modified,导致CPU0 cache 状态已经变成了 Invalid
- CPU0需要重新发出Read请求读取Cache Line后继续写入,这时CPU1会响应自己修改后的最新cache line,同时写回主存
- CPU0获得CPU1修改后的cache line,将i值1写入,导致覆盖掉了CPU1 的自增结果
- 最终两个i++操作之后,i的值还是 1。
使用LOCK前缀指令可以解决这个问题,下文会详细介绍。
性能问题
CPU修改Cache Line中的变量时,要通过总线发送Invalidate信息给远程CPU,等到远程CPU返回ACK,才能进行继续修改。如果远程的CPU比较繁忙,会带来更大的延迟。
为了解决这个问题,引入了Store buffer。
Store buffer和Invalidate queue
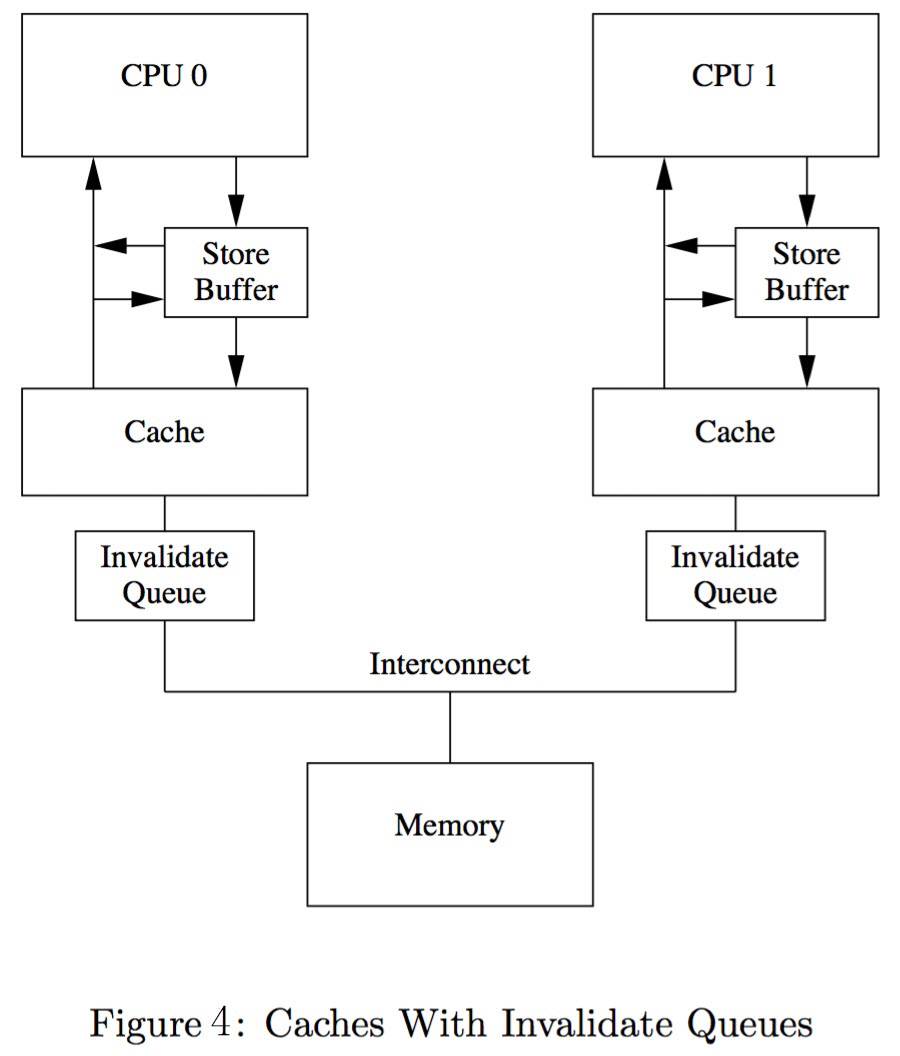
Store buffer
在CPU和L1Cache之间引入Store buffer来对cache line的写操作进行优化。
- 写操作写入Store Buffer后就返回,同时向其它核心发出Invalidate消息。
- 等CPU的Invalidate ACK消息返回后再异步写进Cache Line
- 核心从Cache中读取前都要先扫描自己的Store buffers来确认是否存在目标行。有可能当前核心在这次操作之前曾经写入cache,但该数据还没有被刷入cache(之前的写操作还在 store buffer 中等待)。
- Store buffer对写操作有明显的优化,但也带来CPU内存一致性的问题(出现内存重排)。
注意,虽然CPU可以读取其之前写入到本地Store buffer中的值,但其它核心并不能在该核心将Store buffer中的内容Flush到Cache之前看到这些值。即
- Store buffer是不能跨核心访问的,CPU看不到其它核心的 Store buffer。
- Store buffer刷入cache前,其它核心最多只知道cache line已失效(收到Invalidate消息)
Invalidate queue
Store Buffer 容量是有限的,当Store Buffer满了之后CPU核心还是要卡住等待Invalidate ACK。
- 接收方响应Invalidate ACK耗时的主要原因是核心需要先将自己cache line状态修改I后才响应ACK
- 如果一个核心很繁忙或者处于S状态的副本特别多,可能所有CPU都在等它的ACK。
CPU优化这个问题的方式是引入Invalid queue,CPU核心先将Invalidate消息放到这个队列并立刻响应Invalidate ACK,但不马上处理,消息只是会被推invalidation队列,并在之后尽快处理。
因此核心可能并不知道在它Cache里的某个Cache Line是Invalid状态的,因为Invalidation队列包含有收到但还没有处理的Invalidation消息。
CPU在读取数据的时候,并不像Store buffer那样读取Invalidate queue。
直觉上,引入Store buffer和Invalidate queue之后,不同核心上运行的线程对cache line的并发读写可以会出现问题,即修改不会同步被其它核心处理。
内存一致性 Memory Consistency
下面两个goroutine执行时,会出现几种可能的结果:
|
|
很显然的几种结果:
|
|
令人意外的结果:
|
|
出现这两种意外结果的原因就是内存重排 Memory Reordering。
内存重排是指内存读写指令的重排,原因分为软件层面的编译器重排和硬件层面的CPU重排。
编译器重排
编译器(compiler)的工作之一是优化我们的代码以提高性能。这包括在不改变程序行为的情况下重新排列指令。因为compiler不知道什么样的代码需要线程安全(thread-safe),所以compiler假设我们的代码都是单线程执行(single-threaded),并且进行指令重排优化并保证是单线程安全的。因此,在不需要compiler重新排序指令的时候,需要显式告诉编译器,这里不需要重排。
对于这段C语言代码
|
|
编译优化后的逻辑可以看作如下形式:
|
|
这就是compiler reordering(编译器重排)。
为什么可以这么做呢?对于单线程来说,a 和 b 的写入顺序,compiler认为没有任何问题,并且最终的结果也是正确的(a == 1 && b == 0),因此编译器才会这么做。
这种compiler reordering在大部分情况下是没有问题的,但是在某些情况下可能会引入问题。
例如使用一个全局变量flag标记共享数据data是否就绪,由于compiler reordering,可能会引入问题。考虑下面的代码(无锁编程):
|
|
假设有2个线程,一个用来更新data的值。使用flag标志data数据已经准备就绪,其他线程可以读取。另一个线程一直调用read_data(),等待flag被置位,然后返回读取的数据data。
如果compiler产生的汇编代码是flag比data先写入内存,即使是单核系统上也会有问题,如:
- 在flag置1之后,data写入之前,系统发生抢占
- 另一个线程发现flag已经置1,认为data的数据已经就绪
- 但实际上读取data的值并不是合法值
为什么compiler还会这么操作呢?因为,compiler不知道data和flag之间有严格的依赖关系,这种逻辑关系是我们人为引入的。
对于下面的代码片段
|
|
编译器有可能优化为下面的样子
|
|
单独看来这两种方式的执行结果是一样的,如果当前只有这一个线程读写X变量,程序的运行结果是符合预期的。
但是,在多线程环境下,假如另一个CPU核心执行了这样的指令
|
|
上面两种情况的输出就不一样了。
以上就是编译器重排带来的问题。在多核场景下,不能轻易判断两个程序是否等价。
为了防止编译器重排导致多线程程序逻辑错误的情况,需要在编码时手动插入
内存屏障,禁止编译器调整屏障两边的读写操作。即,内存屏障也具有编译器屏障的效果。
|
|
barrier()就像是代码中的一道不可逾越的屏障,barrier前的 load/store 操作不能跑到barrier后面;同样,barrier后面的 load/store 操作不能跑到barrier之前。
CPU重排
CPU重排是一种运行时的内存重排序。
由于CPU Store Buffer/Invalidate queue的存在,CPU对一个变量的赋值操作可能无法被另一个核心及时观察到,造成出现开头内存重排的另外两种令人意外的结果。这是CPU重排现象的一种原因。
另外,CPU还有流水线、分支预测、乱序等特性,他们的目的都是最大化提高CPU利用率,但也带来了CPU重排的现象,造成内存一致性memory consistency问题,这些是MESI协议解决不了的。
写屏障
|
|
假设有如下执行步骤:
- 假定当前a存在于cpu1的cache中,flag存在于cpu0的cache中,状态均为E。
- cpu1先执行while(!flag),由于flag不存在于它的cache中,所以它发出Read flag消息
- cpu0执行a=1,它的cache中没有a,因此它将a=1写入Store Buffer,并发出Invalidate a消息
- cpu0执行flag=true,由于flag存在于它的cache中并且状态为E,所以将flag=true直接写入到cache,状态修改为M
- cpu0接收到Read flag消息,将cache中的flag=true发回给cpu1,状态修改为S
- cpu1收到cpu0的Read Response:flat=true,结束while(!flag)循环
- cpu1打印a,由于此时a存在于它的cache中a=0(且认为是合法状态),所以打印出来了0
- cpu1此时收到Invalidate a消息,将cacheline状态修改为I,但为时已晚
- cpu0收到Invalidate ACK,将Store Buffer中的数据a=1刷到cache中
从结果看,代码好像变成了
|
|
即两个写入操作发生了重排序。
CPU从软件层面提供了写屏障write memory barrier指令来解决上面的问题,Linux将CPU写屏障封装为smp_wmb()函数。
写屏障解决上面问题的方法是等待当前Store Buffer中的数据同步刷到cache后再执行屏障后面的写入操作。
这里可能会有疑问,上面的问题是硬件问题,CPU为什么不从硬件上自己解决问题而要求软件开发者通过指令来避免呢?
其实很好回答:CPU不能为了这一个方面的问题而抛弃Store Buffer带来的巨大性能提升,就像CPU不能因为分支预测错误会损耗性能增加功耗而放弃分支预测一样。
还是以上面的代码为例,前提保持不变,这时加入写屏障:
|
|
当cpu0执行flag=true时,由于Store Buffer中有a=1还没有刷到cache上,所以会先等待a=1刷到cache之后再执行flag=true,当cpu1读到flag=true时,a也就=1了。
读屏障
现在考虑Invalidate queue带来的问题,还是以上面的代码为例。
我们假设a在CPU0和CPU1中,且状态均为S,flag由CPU0独占
- CPU0执行a=1,因为a状态为S,所以它将a=1写入Store Buffer,并发出Invalidate a消息
- CPU1执行while(!flag),由于其cache中没有flag,所以它发出Read flag消息
- CPU1收到CPU0的Invalidate a消息,并将此消息写入了Invalid Queue,接着就响应了Invlidate ACK
- CPU0收到CPU1的Invalidate ACK后将a=1刷到cache中,并将其状态修改为了M
- CPU0执行到smp_wmb(),由于Store Buffer此时为空所以就往下执行了
- CPU0执行flag=true,因为flag状态为E,所以它直接将flag=true写入到cache,状态被修改为了M
- CPU0收到了Read flag消息,因为它cache中有flag,因此它响应了Read Response,并将状态修改为S
- CPU1收到Read flag Response,此时flag=true,所以结束了while循环
- CPU1打印a,由于a存在于它的cache中且状态为S,所以直接将cache中的a打印出来了,此时a=0,这显然发生了错误。
- CPU1这时才处理Invalid Queue中的消息将a状态修改为I,但为时已晚
为了解决上面的问题,CPU提供了读屏障指令,Linux将其封装为了smp_rwm()函数。
|
|
CPU执行到smp_rwm()时,会将Invalid Queue中的数据处理完成后再执行屏障后面的读取操作,这就解决了上面的问题了。
除了上面提到的读屏障和写屏障外,还有一种全屏障Full barrier,它其实是读屏障和写屏障的综合体,兼具两种屏障的作用,在Linux中它是smp_mb()函数。
前面提到的LOCK前缀指令其实兼具了内存屏障的作用。
CPU重排问题靠是MESI协议解决不了的,还是需要使用
内存屏障技术,在需要时同步Flush Store buffer和Invalidate queue。
CPU内存一致性模型
cache一致性和内存一致性有什么区别呢?
可以简单地认为,cache一致性关注的是多个CPU看到一个地址的数据是否一致,而内存一致性更多关注的是多个CPU看到多个地址数据读写的次序是否一致。
针对内存一致性问题,提出内存一致性模型的概念,方便软件工程师在不理解硬件的情况下,基于硬件的内存一致性模型编写正确的并行代码。
内存一致性模型讨论的是,在引入Store buffer等CPU乱序机制后,指令流的定义顺序与CPU实际执行顺序的一致性问题。
目前有多种内存一致性模型。不同的处理器平台,本身的内存模型也有强Strong弱Weak之分。
- 顺序存储模型 Sequential Consistency
- 最强一致性,没有乱序存在,严重限制硬件对CPU的优化
- 完全存储定序 Total Store Order
- Strong Memory Model,强内存模型,如X86/64,保证每条指令的acquire/release语义
- 部分存储定序 Part Store Order
- 宽松存储模型 Relax Memory Order
- Weak Memory Model,弱内存模型,如ARM/PowerPC
分类
以下面的例子为例介绍这几种模型的处理方法

顺序存储模型SC
多核心会完全按照指令流的顺序执行代码。上面例子的执行顺序是
|
|
- C1与C2的指令虽然在不同的CORE上运行,但是C1发出来的访问指令是顺序的,同时C2的指令也是顺序的
- 虽然这两个线程跑在不同的CPU上,但是在顺序存储模型上,其访问行为与UP(单核)上是一致的 所以在顺序存储模型上是不会出现内存访问乱序的情况。
完全存储定序TSO
TSO会利用Store buffer提高CPU利用率,并且严格按照FIFO的顺序将Store buffer中的Cache Line写入主存。
|
|
在顺序存储模型中,S1肯定会比S2先执行。
但是加入了Store buffer之后,S1将指令放到了Store buffer后会立刻返回,这个时候会立刻执行S2。S2是read指令,CPU必须等到数据读取到r1后才会继续执行。这样很可能S1的store flag=set指令还在Store Buffer上,而S2的load指令可能已经执行完(特别是data在Cache上存在,而flag没在Cache中的时候。这个时候CPU往往会先执行S2减少等待时间)。
加入了store buffer之后,内存一致性模型就发生了改变。
完全存储定序TSO要求,严格按照FIFO的次序将数据发送到主存(先进入Store Buffer的指令数据必须先于后面的指令数据写到存储器中),这样S3必须要在S1之后执行。
CPU只保证Store指令的存储顺序,即完全存储定序(TSO)。而对于Store指令后面有Load指令的情况,CPU可能会将Load指令提前执行完成。这就是所谓的 Store-Load 乱序,x86 唯一的乱序就是这种。
关于x86架构的强内存序:
- x86架构不存在invalidate queue,因此不存在 Load-Load/Load-Store乱序
- store buffer严格按照FIFO,因此不存在Store-Store乱序
- 由于store buffer,存在Store-Load乱序
部分存储定序PSO
芯片设计人员并不满足TSO带来的性能提升,于是他们在TSO模型的基础上继续放宽内存访问限制,允许CPU以非FIFO来处理Store buffer缓冲区中的指令。CPU只保证地址相关指令在Store buffer中才会以FIFO的形式进行处理,而其他的则可以乱序处理,所以这被称为部分存储定序(PSO)。
这里的地址相关指令,指多个指令操作的地址相同或者有前后关联。例子中L1和L2就是地址无关指令。
这时可能出现这样的执行顺序,即Store-Store乱序。
|
|
由于S2可能会比S1先执行,从而会导致C2的r2寄存器获取到的data值为0。
宽松存储模型RMO
在PSO的模型的基础上,更进一步的放宽了内存一致性模型,不仅允许Store-Load,Store-Store乱序。还进一步允许Load-Load,Load-Store乱序。只要是地址无关的指令,在读写访问时都可以打乱所有Load/Store的顺序,这就是宽松内存模型(RMO)。
RMO内存模型里乱序出现的可能性会非常大,这是一种乱序随处可见的内存一致性模型。
Acquire/Release 语义
Acquire语义是指从共享内存中读取数据,无论是读-修改-写还是直接load。这些操作都被归类为read acquire。 Acquire语义保证了read-acquire操作不会被程序后续的任何read或write操作打乱顺序。
Release语义是指向共享内存中写入数据,无论是读-修改-写还是直接store。这些操作都被归类为write-release。 Relase语义保证了write-release操作不会被程序前面的任何read或write操作打乱顺序。

x86只有Store-Load乱序,因此x86上每条指令都符合acquire和release语义。
内存模型的重要性
内存一致模型,或称内存模型,是一份语言用户与语言自身、语言自身与所在的操作系统平台、 所在操作系统平台与硬件平台之间的契约。它定义了并行状态下拥有确定读取和写入的时序的条件, 并回答了一个共享变量是否具有足够的同步机制来保障一个线程的写入能否发生在另一个线程的读取之前这个问题。
在一份程序被写成后,将经过编译器的转换与优化、所运行操作系统或虚拟机等动态优化器的优化,以及 CPU 硬件平台对指令流的优化才最终得以被执行。这个过程意味着,对于某一个变量的读取与写入操作,可能 被这个过程中任何一个中间步骤进行调整,从而偏离程序员在程序中所指定的原有顺序。 没有内存模型的保障,就无法正确的推演程序在最终被执行时的正确性。
内存模型的策略同样有着长期影响,并且直接决定了程序的可移植性和可维护性。 例如,过强的内存模型将约束硬件和编译器优化的空间,从而严重降低程序性能上限; 已经选择了强内存模型的硬件体系结构,无法在不破坏兼容性的情况下向更弱的内存模型进行迁移, 这种兼容性破坏所带来的代价就是要求其平台上的程序重新实现其源码。
这种横跨用户、软件与硬件三大领域的主题使得内存模型的设计愿景变得异常的困难,至今仍是一个开放的研究问题。
在 Go 语言中不需要操心这个问题,Go 语言的 sync/atomic 提供最强的内存序保证(借助各CPU平台上的内存屏障指令),即 sequential consistency。该一致性保证由 Go 保证,在所有运行 Go 的硬件平台上都是一致的。
如今主流的编程语言的内存模型都是顺序一致性(SC)模型,它为开发人员提供了一种理想的SC机器(虽然实际中的机器并非SC的),程序是建构在这一模型之上的。开发人员要想实现出正确的并发程序,还必须了解编程语言封装后的同步原语以及他们的语义。只要程序员遵循并发程序的同步要求合理使用这些同步原语,那么编写出来的并发程序就能在非SC机器上跑出顺序一致性的效果。
内存屏障
芯片设计人员为了尽可能的榨取CPU的性能,引入了乱序的内存一致性模型,这些内存模型在多线程的情况下很可能引起软件逻辑问题。
为了解决在有些一致性模型上可能出现的内存访问乱序问题,芯片设计人员提供给了内存屏障指令。 内存屏障的最根本的作用就是提供一个机制,要求CPU在这个时候必须以顺序存储一致性模型的方式来处理Load与Store指令,这样才不会出现内存不一致的情况。
对于TSO和PSO模型,内存屏障只需要在Store-Load/Store-Store时需要(写内存屏障),最简单的一种方式就是内存屏障指令必须保证Store buffer数据全部被清空的时候才继续往后面执行,这样就能保证其与SC模型的执行顺序一致。
而对于RMO,在PSO的基础上又引入了Load-Load与Load-Store乱序。RMO的读内存屏障就要保证前面的Load指令必须先于后面的Load/Store指令先执行,不允许将其访问提前执行。
memory barrier 是必须的。一个 Store barrier 会把 Store Buffer flush 掉,确保所有的写操作都被应用到 CPU 的 Cache。一个 Read barrier 会把 Invalidation Queue flush 掉,也就确保了其它 CPU 的写入对执行 flush 操作的当前这个 CPU 可见。
内存屏障类型
从上面来看,barrier 有四种:
- LoadLoad 阻止不相关的 Load 操作发生重排
- LoadStore 阻止 Store 被重排到 Load 之前
- StoreLoad 阻止 Load 被重排到 Store 之前
- StoreStore 阻止 Store 被重排到 Store 之前
内存屏障指令
Intel为此提供四种内存屏障指令:
- sfence ,实现Store Barrier。将Store Buffer中缓存的修改刷入L1 cache中,使得其他cpu核可以观察到这些修改,而且之后的写操作不会被调度到之前,即sfence之前的写操作一定在sfence完成且全局可见;
- lfence ,实现Load Barrier。 Flush Invalidate Queue,强制读取L1 cache,而且lfence之后的读操作不会被调度到之前,即lfence之前的读操作一定在lfence完成(并未规定全局可见性);
- mfence ,实现Full Barrier。 同时刷新Store Buffer和Invalidate Queue,保证了mfence前后的读写操作的顺序,同时要求mfence之后的写操作结果全局可见之前,mfence之前的写操作结果全局可见;
- lock 用来修饰当前指令操作的内存只能由当前CPU使用,若指令不操作内存仍然有用,因为这个修饰会让指令操作本身原子化,而且自带Full Barrior效果;还有指令比如IO操作的指令、CHG等原子交换的指令,任何带有LOCK前缀的指令以及CPUID等指令都有内存屏障的作用。
X86-64下仅支持一种指令重排:Store-Load ,即读操作可能会重排到写操作前面,同时不同线程的写操作不保证全局可见,这个问题只能用mfence解决,不能靠组合sfence和lfence解决。
由此可见,
LOCK前缀指令即保证的RMW类操作的原子性,又有内存屏障的作用。
解决 cache coherence 的协议(MESI)并不能解决 CAS 类的问题。同时也解决不了 memory consistency,即不同内存地址读写的可见性问题,要解决 memory consistency 的问题,需要使用 memory barrier 之类的工具。
LOCK前缀指令
X86 CPU 上具有锁定一个特定内存地址的能力,当这个特定内存地址被锁定后,就可以阻止通过系统总线读取或修改这个内存地址。这种能力需要显式在某些汇编指令上使用LOCK前缀获得。
当使用 LOCK 指令前缀时,它会使 CPU 宣告一个 LOCK# 信号,这样就能确保在多处理器系统或多线程竞争的环境下互斥地使用这个内存地址。指令执行完毕,锁自动释放。
支持使用LOCK前缀的指令有ADD/OR/AND/SUB/INC/NOT等,另外XCHG/XADD自带LOCK效果。
另外,Intel在原有总线锁的基础上做了一个很有意义的优化:如果要访问的内存区域在lock前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,其它处理器无法读/写该指令要访问的内存区域,因此能保证指令执行的原子性。这个操作过程叫做缓存锁定(cache locking),缓存锁定将大大降低lock前缀指令的执行开销。但是当多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。
假设两个CPU核心都持有相同的Cache Line,且各自状态为S, 这时如果要想执行 LOCK 指令,成功修改内存值,就首先需要把S转为E或者M, 则需要向其它核心 Invalidate 这个地址的Cache Line,则两个core都会向总线发出 Invalidate这个操作。总线会根据特定的设计协议仲裁是CPU0还是CPU1能赢得这个invalidate,胜者完成操作, 失败者需要接受结果并Invalidate自己对应的Cache Line,再读取胜者修改后的值继续执行。
通过LOCK前缀,可以使RMW类的操作具备原子性:
Unlocked increment:
- Acquire cache line, shareable is fine. Read the value.
- Add one to the read value.
- Acquire cache line exclusive (if not already E or M) and lock it.
- Write the new value to the cache line.
- Change the cache line to modified and unlock it.
Locked increment:
- Acquire cache line exclusive (if not already E or M) and lock it.
- Read value.
- Add one to it.
- Write the new value to the cache line.
- Change the cache line to modified and unlock it.
除此之外,LOCK指令还有禁止该指令与之前和之后的读和写指令重排序、把Store Buffer中的所有数据刷新到内存中的功能(可见性),是实现内存屏障的方式之一。
总之,LOCK前缀提供了原子性和可见性保证。
Go中的原子读写
以amd64平台上的Store64/Load64为例:
|
|
|
|
由于x86平台是acquire/release语义,只存在Store-Load乱序,所以Go在amd64平台上:
- 实现Store64时,使用XCHG(with LOCK# prefix)方式提供内存屏障
- 实现Load64时,因为内存对齐的读取是原子的,而且在Store时使用了内存屏障,所以这里可以直接读取,不需要再使用内存屏障。
在PowerPC上,可以看到Load64操作使用了SYNC内存屏障
|
|
再来看下32位的i386平台上的实现:
|
|
可以看到,Store64中同样使用了LOCK指令。而在Load64中,先检查了内存是否对齐,再执行MOVQ操作。
在i386上如何保证64位数MOV操作的原子性呢? 在sync/atomic包描述 中有这样的介绍:
On ARM, 386, and 32-bit MIPS, it is the caller’s responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically via the primitive atomic functions (types Int64 and Uint64 are automatically aligned). The first word in an allocated struct, array, or slice; in a global variable; or in a local variable (because the subject of all atomic operations will escape to the heap) can be relied upon to be 64-bit aligned.
传给 sync/atomic 的 64 位函数的地址必须是 64 位对齐的,否则调用这些函数会引起运行时panic。
- 对于运行在 64 位系统的 Go 程序,64 位值确保为 64 位对齐,所以他们可以被原子访问。
- 对于运行在 32 位系统的 Go 程序,没有64位对齐保证,需要由调用方保证64位对齐才能被原子访问。32位系统上以下的 64 位字可以确保能够原子访问:
- 已分配 64 位字
- 已分配结构体的第一个字段是 64 位字
- 已分配数组的第一个元素的第一个字是 64 位
这里, 一个已分配值意味着该值的地址是该值所在内存块的开始地址,即该值在内存块所在的开始位置。详细参考这里 。
一条汇编指令是原子的吗
read-modify-write 内存的指令不是原子性的,以INC mem_addr为例,我们假设数据已经缓存在了cache上,指令的执行需要先将数据从cache读到执行单元中,再执行+1,然后写回到cache。
对于没有对齐的内存,读取内存可能需要多次读取,也不是原子性的。(在某些CPU上读取未对齐的内存是不被允许的)
例子
|
|
使用race检测,该代码第二个if处存在data race。
原因是在 instance = &UserInfo{Name: "test"} 这句代码,这句代码并不是原子操作,这个赋值可能是会有几步指令,比如
- 先 new 一个
UserInfo - 然后设置
Name="test" - 最后把了 new 的对象赋值给
instance
如果这个时候发生了乱序,可能会变成
- 先了 new 一个
UserInfo - 然后再赋值给
instance - 最后再设置
Name="test"
A 进程进来的时候拿到锁,然后对 instance 进行赋值,这个时候 instance 对象是一个半初始化状态的数据,线程 B 来的时候判断 if instance == nil 发现不为 nil 就直接把半初始化状态的数据返回了,所以会有问题。
|
|
这里主要是通过 atomic.Store 和 Lock 来保证 flag 和 instance 的修改对其他线程可见。
通过 atomic.LoadUint32(&flag) 和 double check 来保证 instance 只会初始化一次。
再次用 go run -race 检查已经没有警告了。
true sharing的性能问题
golang目前有一个issue 17973 ,RWMutex的RLock方法在CPU核心数量变多时,性能下降严重
|
|
原因在于对rw.readerCount变量的内存争用上。
在核心数增多时,单次atomic操作的成本上升,导致程序整体性能下降。
atomic.Add使用Lock指令构建内存屏障,同步刷新CPU Store Buffer防止出现CPU重排现象。超多核心场景下,MESI协议下某个核心等待其它CPU的操作响应,导致单个操作成本提高,影响多核性能。
参考链接
if-aligned-memory-writes-are-atomic-why-do-we-need-the-sync-atomic-package