Cassandra 笔记[下]
文章目录
写操作
基于MemTable和SSTable的设计,Cassandra写磁盘都是顺序写,没有seek操作,使得写操作非常快速。 基于commitlog和hinted handoff的基址,写入总是高可用的。在每个row中,写操作是原子的。
Cassandra提供了可调一致性,在执行写操作时可以指定想要的一致性级别。在更高的一致性下,需要同步写入更多的节点,同时也降低了可用性。
- ANY 最少写入一个节点,即使是hinted handoff情况
- ONE/TWO/THREE
- LOCAL_ONE 本地DC
- QUORUM
- LOCAL_QUORUM 本地DC
- EACH_QUORUM 每个DC
- ALL 写入replication factor的所有副本
写请求处理流程
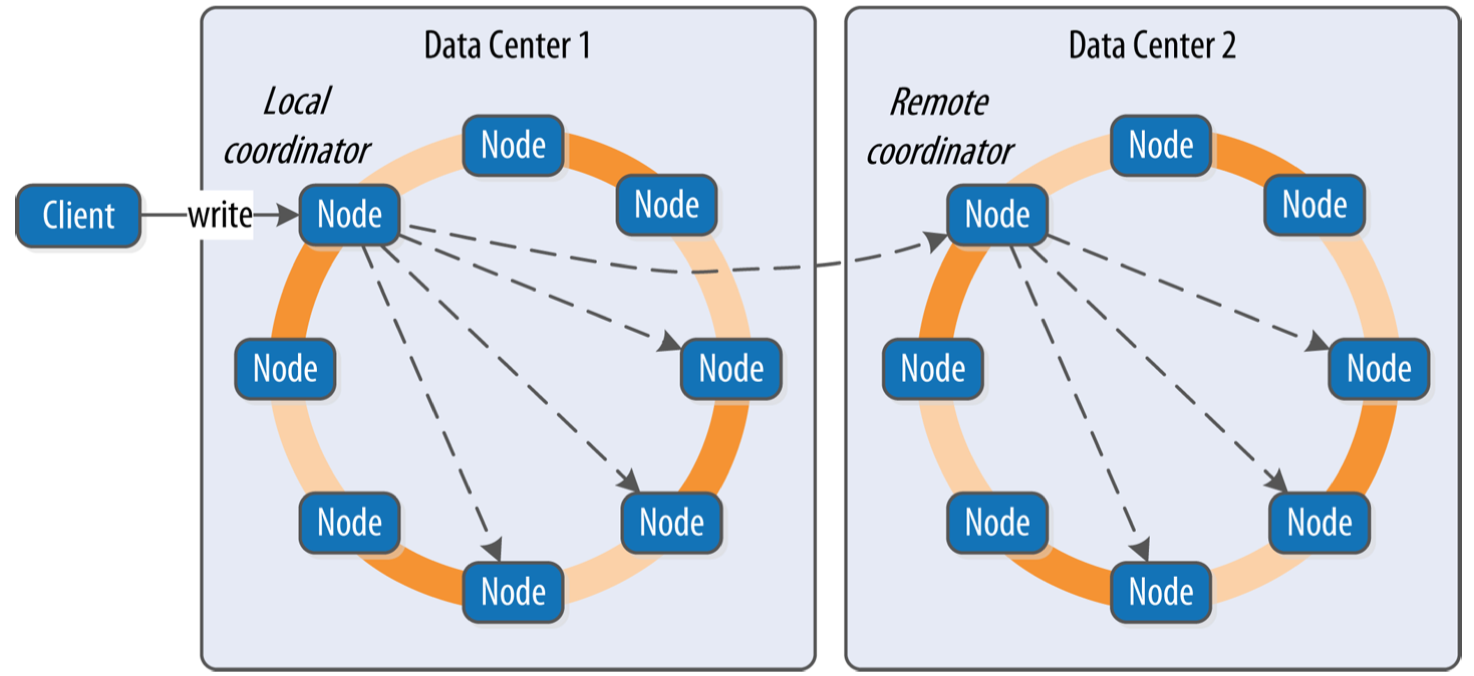
- 客户端连接集群中的某个节点作为协调节点,协调节点使用partitioner确定哪些节点包含对应的副本
- 协调器向本地副本发送写请求,如果是多DC,本地协调器会选择其它每个DC的远程协调器,向它们发送写请求
- 在线的需要写入的副本都会收到写请求,对于不在线的节点,会出现不一致的数据,将会被 hinted handoff/read repair/anti-entropy repair 其中的某种机制修复
- 协调器等待副本响应,一旦达到一致性级别要求的副本数量,即可向客户端回复。
- 如果某个节点下线,会为它生成hint
副本节点内部的处理流程
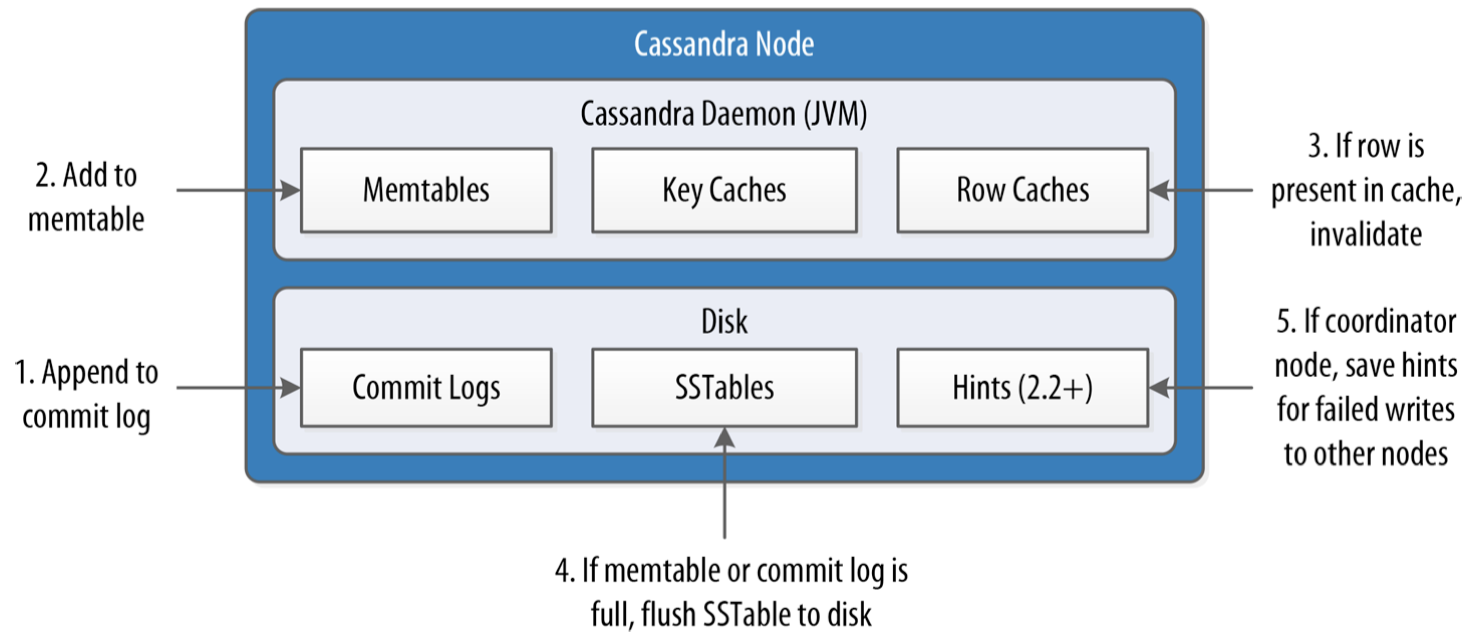
- 副本节点收到写请求后,立即写入commitlog,然后再写入memTable
- 如果使用了row caching并且row被缓存,则cache中对应的row失效
- 如果commitlog或memTable达到阈值,则执行flush操作
- 此时即认为写操作在本节点成功,回复协调节点
另外,
- 在某个时刻,节点执行flush操作,每个memTable将会被刷到磁盘的SSTable中,然后清空commitlog。
- 在flush结束后,检查是否需要执行compaction
磁盘文件
commit log
- 文件名格式:CommitLog-
.log
SSTable
- flush会生成SSTable,每个SSTable包含一组文件
- 文件命名
- - .db - 每次生成新的SSTable时,generation都会递增
- component的可能类型
- Data.db SSTable数据文件,在Cassandra备份时,仅备份该文件
- CompressionInfo.db 包含对Data.db压缩情况的元数据
- Digest.crc32 db文件校验
- Filter.db 该SSTable的bloom过滤器
- Index.db 数据文件内row和column的索引,会加载到内存中
- Summary.db 保存index的摘要
- Statistics.db 统计数据
- TOC.txt 该SSTable的component列表
Lightweight Transactions
LWT基于Paxos算法,支持以下语义
- INSERT语句中的IF NOT EXISTS语句保证不会覆盖相同primary key的记录
- INSERT语句中的IF EXISTS则仅在primary key存在时执行
- UPDATE语句中的IF
语句可以在写入执行前提供检查操作,并保证读写的原子性,可以用于扣库存操作 - 如果条件检查失败,语句会返回当前值,用户程序可以判断是否重试或终止
以上的条件写语句,可以格外指定顺序一致性级别 serial consistency level,用来决定在Paxos协商阶段参与的节点数量
- SERIAL 至少quorum个节点
- LOCAL_SERIAL 每个DC至少quorum个节点
Batches
batch操作将多个修改放在一个语句,用来降低客户端和协调器之间的网络耗时。
LWT限制了仅在一个partition上使用,而batch机制允许将多个修改请求放在同一个语句中,且可以跨partitions。
- 只有修改操作 INSERT/UPDATE/DELETE 操作可以放在batch中
- 分为logged/unlogged
- batch不提供事务,但允许将LWT语句放在batch中执行。batch中的多个LWT必须使用同一个partition。
- batch有尺寸上限
使用场景
- 对单个partition做多次更新
- 保持多个表同步
- 更新具有相同partition key的不同表
注意,batch操作并不会提升修改的性能,它只是避免多次请求的网络延时。batch实际上会损耗性能并导致GC。
关于logged batch和unlogged batch
- logged batch
- 协调器发送batch的拷贝(batchlog)给另外两个节点,如果协调器执行batch失败,另外两个节点会定时判断是否有未完成的batch需要执行
- logged会给协调器增加编排负担;使用 BEGIN BATCH – APPLY BATCH 包裹多条语句。
- logged batch提供同一个partition下多个修改操作的原子性。对于不同partition的操作,可能在batch执行结束前就能被读到。
- unlogged batch
- 不涉及batchlog的操作,适用于快速插入大量数据
- 不保证不同partition的所有数据都会成功写入,如果batch仅写一个partition就不会有问题
读操作
客户端可以连接集群中的任一节点进行读操作,如果该节点没有需要的数据,则作为协调器去目标节点读取数据。
由于读取SSTable需要文件IO,读操作比写操作要慢。可以通过增加节点、增加内存、使用cache的方式让更多的数据留在内存。
根据一致性级别和副本因子,读操作需要同步等待若干节点的相应,并根据需要执行read repair。
Read Consistency Levels
更高的一致性级别意味着需要读取更多的节点,来保证读到准确的数据。如果两个节点返回值的时间戳不同,则选择时间戳最新的那个。 如果发现旧数据,会执行 read repair进行修复。
读一致性级别:
- ONE/TWO/THREE 立即返回第一个响应的节点的值,然后在其他副本上检查一致性,对于过期数据执行read repair。可能读到旧值。
- LOCAL_ONE 本地DC的一个节点
- QUORUM 读取所有节点,多数节点响应后,返回最近的时间戳,必要时对剩余节点执行read repair
- LOCAL_QUORUM 类似QUORUM,只要求本地DC
- EACH_QUORUM 要求每个DC的多数节点响应
- ALL 读取并等待所有节点响应,返回最近的时间戳并进行read repair
可调的读写一致性级别可以实现一致性和性能之间的权衡。
读请求处理流程
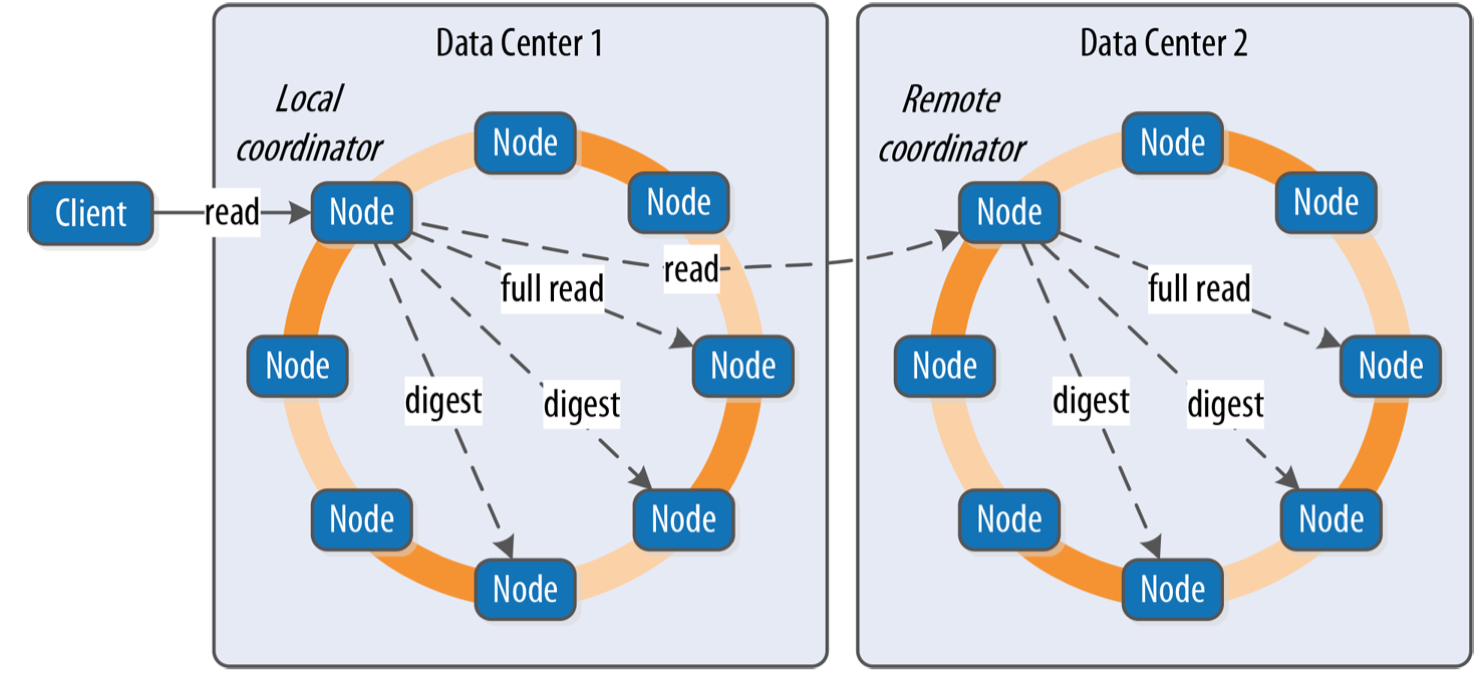
- 客户端向某个节点发送读请求,该几点作为协调器节点
- 根据partition确定副本位置,检查是否有足够的副本满足一致性级别要求
- 如果一致性要求多DC的读取,协调器还会请求其它DC的协调器执行读请求
- 如果协调器不是目标副本,会向最快副本发送读请求(由dynamic snitch决定哪个副本是最快的)
- 向剩余副本发送digest request请求来获取目标数据的哈希值
- 协调器计算最快副本返回的结果的哈希值,和其它副本返回的哈希值对比
- 如果相同,且符合一致性级别要求,则返回客户端
- 如果不同,在返回结果后执行read repair
读请求内部处理流程
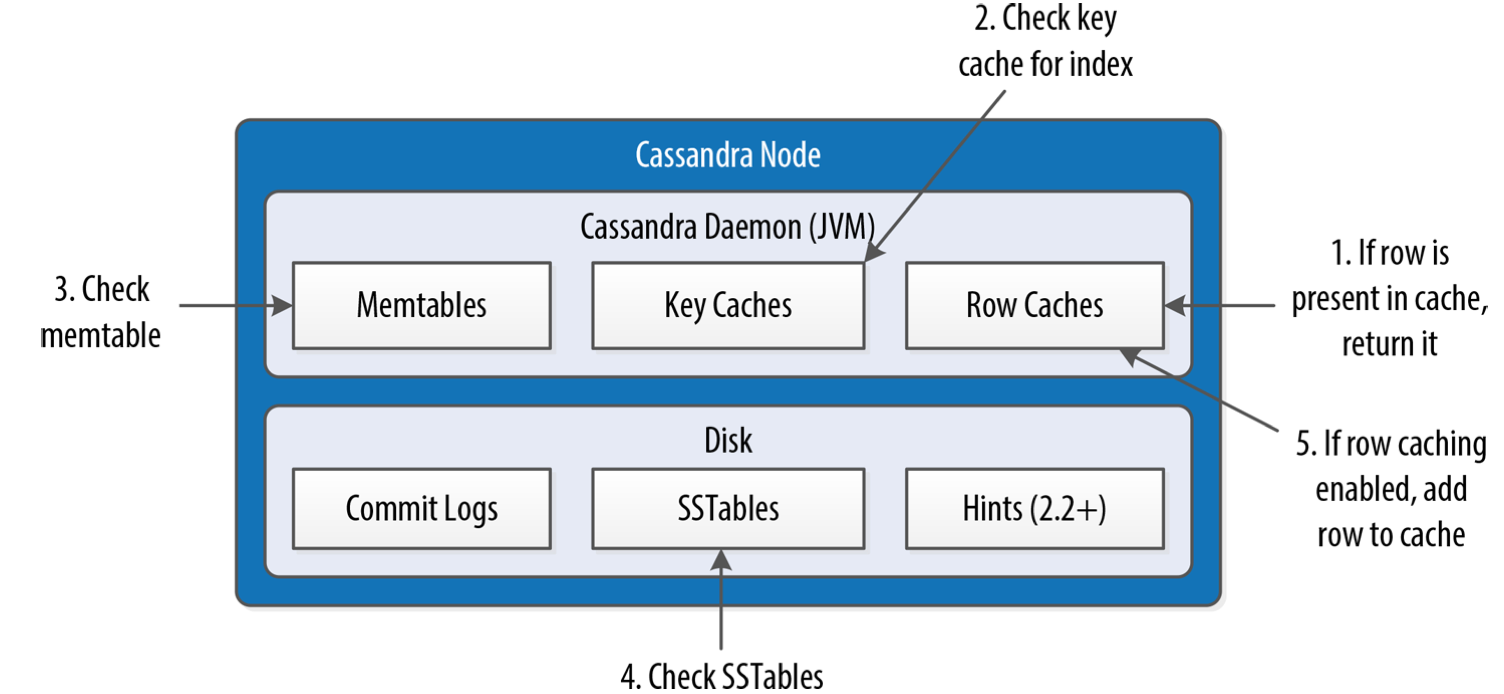
- 副本节点收到读请求后,首先检查row cache,如果包含数据,直接返回
- 在memTables和SSTables中查询
- 一个表对应一个内存memTable,但是可能对应多个SSTable
- 加速SSTable读取的几个特性
- key caching/bloomguolqi/SSTable index/summary index
- 通过bloom过滤器检查是否在当前SSTable不存在需要的partition
- 检查key cache中是否存在partition key对应的offset
- 如果key cache中不存在对应关系,则通过summary index根据partition获取offset
- 根据offset去SSTable中获取数据
从SSTable读取数据后,Cassandra会从memTable及SSTable中选择时间戳最近的值进行合并。 最终将合并后的结果返回给客户端或者协调节点。
对于digest的读请求,仅需要返回结果的哈希值。
Read Repair
- 协调者向多个副本发起读请求后,会检查值的时间戳并返回最新的值
- 如果同一个时间戳发现了不同的值,则选择字段序最大的那个返回。这种情况很少出现。
- 如果副本返回的值不同,则发起read repair
- read repair可能在响应客户端之前或者之后执行,取决于使用的一致性级别
- 对于QUORUM/ALL级别,需要在返回客户端之前修复
- 对于弱一致性级别(ONE等),可以在返回客户端后在后台执行
Range Queries, Ordering and Filtering
假如有这样的表定义约束
|
|
则partition key为hotel_id,clustering column为date和room_number。
以下查询是合法的:
|
|
以下查询是非法的:
|
|
WHERE字句有两个规则:
- partition key中的所有元素都必须给定值
- clustering column中,如果有某个元素没有指定条件,则不允许对其后的元素指定条件
这个限制基于Cassandra在磁盘上存储数据的方式,是基于partition key分区,基于clustering column排序的,只能读取连续的rows。
当然也可以使用ALLOW FILTERING打破这个限制,但是不建议使用,因为性能极差。此时应该考虑修改表定义。
|
|
IN字句可以用来指定column的多个可能取值
|
|
如果在partition key上使用IN字句,会导致协调节点和大量的节点通信。此时应该考虑将查询按partition key拆分成多个并行的查询。
SELECT允许对clustering column列的结果重排序
|
|
Paging
对于分页操作,一般使用客户端库的API操作。
- 如果在服务端分页,可以使用分页对象page在内存中操作
- 如果在请求方分页,服务端无法保存状态,可以将page对象加密序列化后发送给请求端,在请求下一页时再发送。
删除操作
Cassandra中的删除,并是不立即移除数据。
- 如果Cassandra的删除设计成立即执行,如果某个节点宕机错过删除事件,在它恢复后会认为其它节点丢失了这个数据的写入(反熵),因此又把记录发送给其它节点,导致记录复活
- Cassandra中使用tombstone墓碑机制执行删除操作
特性:
- 墓碑是在DELETE操作时放置了一个特殊的标记,如果有副本没有收到删除请求,在副本节点恢复后,将会收到来自其它节点的墓碑信息。
- 因此DELETE操作相当于一次写操作
- 墓碑的副作用是,数据存储空间不会在DELETE操作后立即减小。
- 每个节点都会跟踪墓碑的时间,默认最长保留10天,此时随着compaction操作的执行,墓碑会被删除,相应的磁盘空间也会被释放
- SSTable无法修改,只会在compaction执行时生成一份新的
- DELETE操作的本质是写入墓碑,因此写操作的一致性级别对于DELETE操作同样适用。
- 在一条命令中删除的数据越多,使用的墓碑越少。
- 如果应用生成了大量的墓碑,将会严重影响读取性能(因为在读取SSTable时需要遍历这些墓碑)
建议:
- 可以在插入数据时指定TTL属性,Cassandra会自动删除过期数据
- 对于有时间序列模式的表,可以使用 TimeWindowCompactionStrategy的压缩策略,允许Cassandra一次性删除完整的SSTable。
DELETE支持不同的粒度:
- 删除一个集合中的数据(set/list/map)
- 删除非主键的column
- 删除完整的row
- 删除符合WHERE字句条件的rows
- 删除一个partition