Cassandra 笔记[上]
文章目录
数据模型
一些概念:
- Column
- 一个键值对name/value pair
- 允许某些键没有值:稀疏存储,
wide column宽列 - 包含附加属性:timestamps和TTL
- 每次插入和更新都会更新column的时间戳,用来在冲突发生时实现last write wins(LWW)策略
- TTL指定column的过期时间
- Row
- 由Primary key确定的一组columns
- Partition
- 存储在同一个Cassandra节点上的一组相关的rows
- Primary Key
- 用来确定一个row
- 由
partition key和clustering columns组成的复合键 - 对于INSERT和UPDATE,必须指定主键的columns以确定row的位置,但可以不指定主键以外的columns
- 如果INSERT时主键对应的row已存在,则相当于更新
- 如果UPDATE时主键对应的row不存在,则相当于插入
- Partition Key
- 可以由多个列组成,用来决定rows存储在Cassandra的哪个节点上。
- 一个partition key下可以有多个rows
- Clustering Columns
- 用来决定partition内数据存储的顺序
- 用来定位partition内的row
- 如果Table中没有指定clustering column,则每个partition下只有一个row
- 例子
- PRIMARY KEY (first_name, last_name)中,partition key为first_name,clustering column为last_name
- PRIMARY KEY((k_part_one, k_part_two), k_clust_one, k_clust_two) 中,k_part_one和k_part_two为联合partition key,k_clust_one和k_clust_two为clustering column
- Static Column
- 用来定义不属于主键,但被partition内的每个row共享的数据
- Secondary Index Column
- Table
- 逻辑相关的rows的集合
- Keyspace
- tables的集合
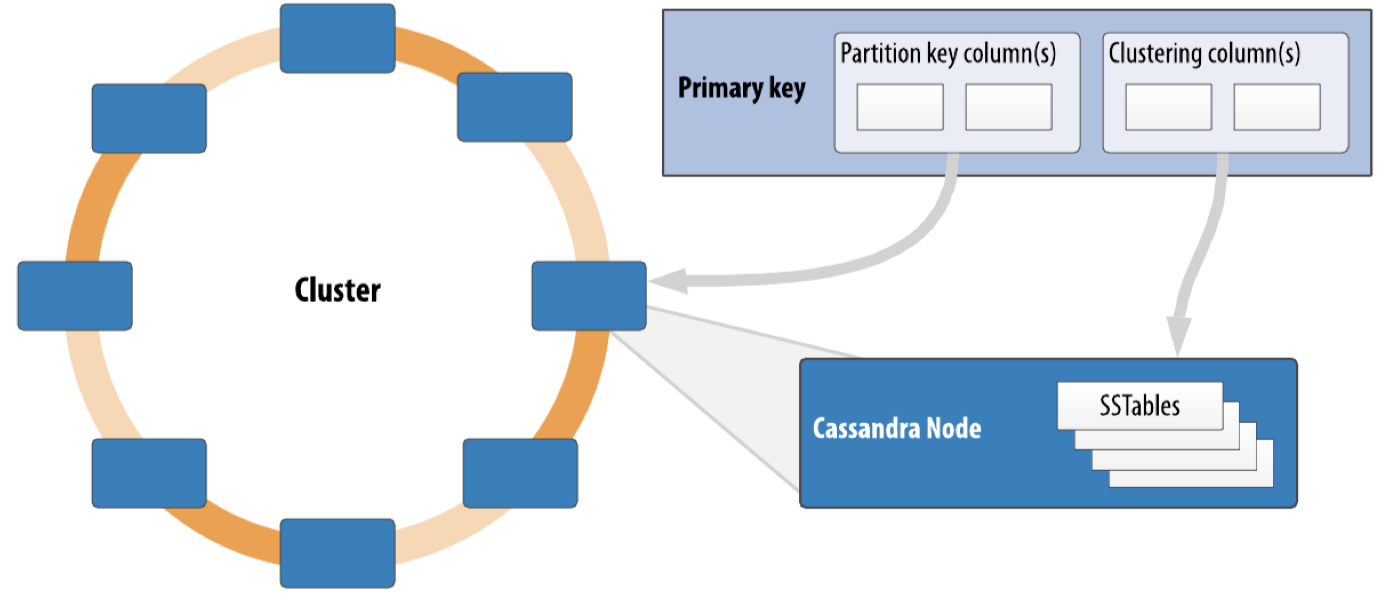
- Cluster
- 存放keyspaces的节点,也叫Ring

架构
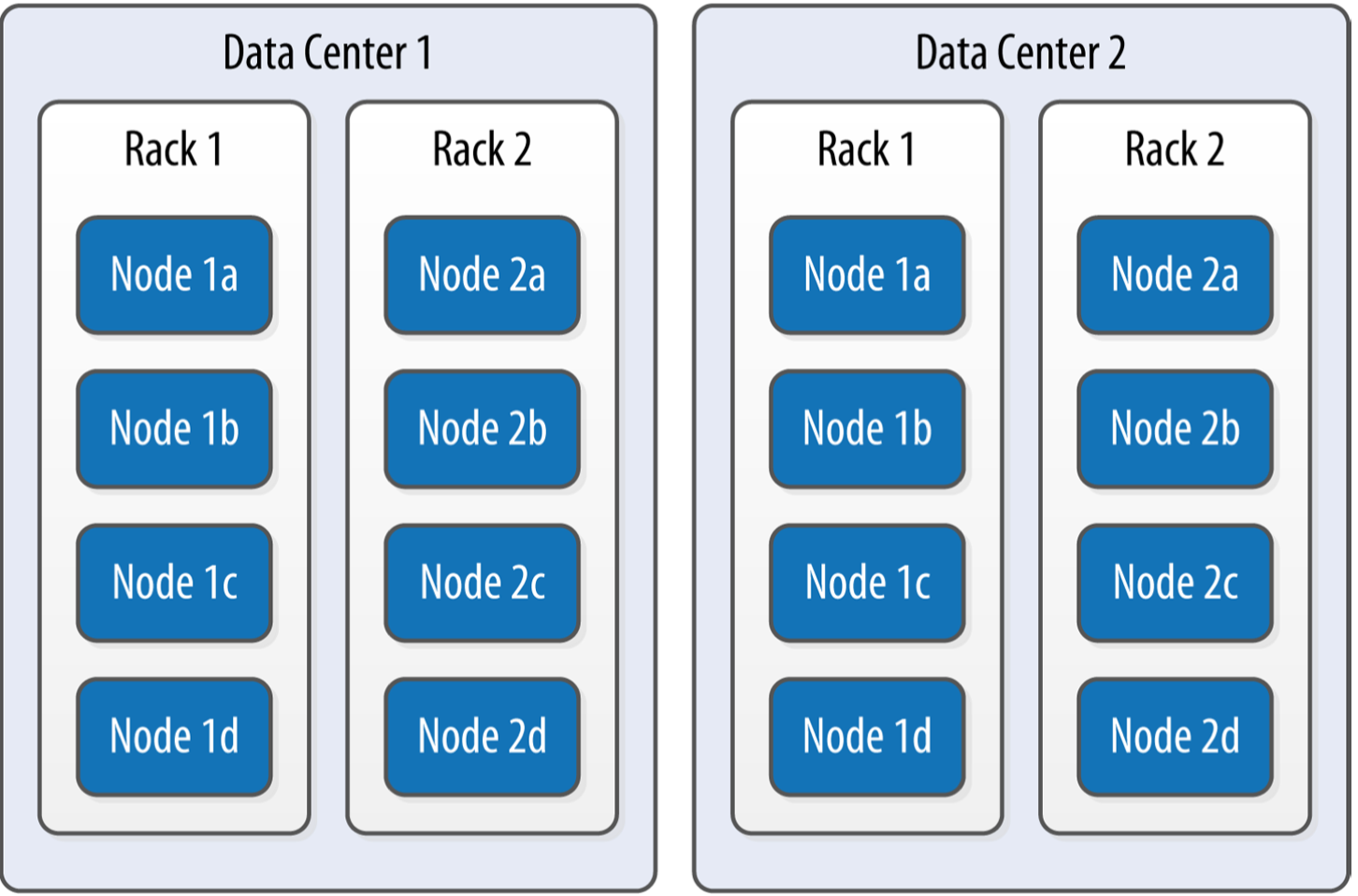
Data Center和Rack
- Rack是一组Cassandra节点的集合,位于同一个机架或者物理机
- DC是一组Rack的集合,通常有独立的基础设施
默认配置是一个DC一个Rack
Gossip和故障发现
Cassandra使用gossip协议在多个节点之间同步信息,也可以用来实现节点的故障发现。
Snitches
根据配置的网络拓扑实现副本节点的识别和快速访问。
Rings和Tokens
基于一致性哈希,token相当于ring上的坐标,每个节点负责维护一段token range上的数据。 token ring
Virtual Nodes
考虑到节点过少造成的数据倾斜问题,以及节点性能差异,使用虚拟节点vnode代替实际节点放在ring上。
Partitioner
决定数据如何在集群的多个节点上分布,使用partition key进行哈希计算。
- partition key用来决定放置在哪个节点
- clustering column用来决定某个node上的rows的顺序,也用来在该节点内定位row
Replication Strategies
使用副本因子replication factor指定数据的副本数。第一个副本位置由一致性哈希决定,其余的副本位置由副本策略决定。
- SimpleStrategy将其余副本放置在哈希环的连续节点
- NetworkTopologyStrategy根据DC和Rack分布放置副本,提供高可用性
Consistency Levels
Cassandra提供可调一致性级别,允许在CAP之间进行权衡。可以指定每个读写请求的一致性级别。
- 对于读请求,一致性级别指定需要从几个节点上读取数据
- 对一写请求,一致性级别指定需要成功写入几个节点
- Cassandra实现的是最终一致性,对其余节点的写入会在后台执行
可选的一致性级别:
- ONE/TWO/THREE
- QUORUM/LOCAL_QUORUM
- ALL
当满足 R+W>ReplicatioFactor时,认为是强一致性,所有的读请求都能读到最近写入的数据,如 QUORUM/LOCAL_QUORUM级别。
一致性级别基于副本因子,而不是系统节点数。
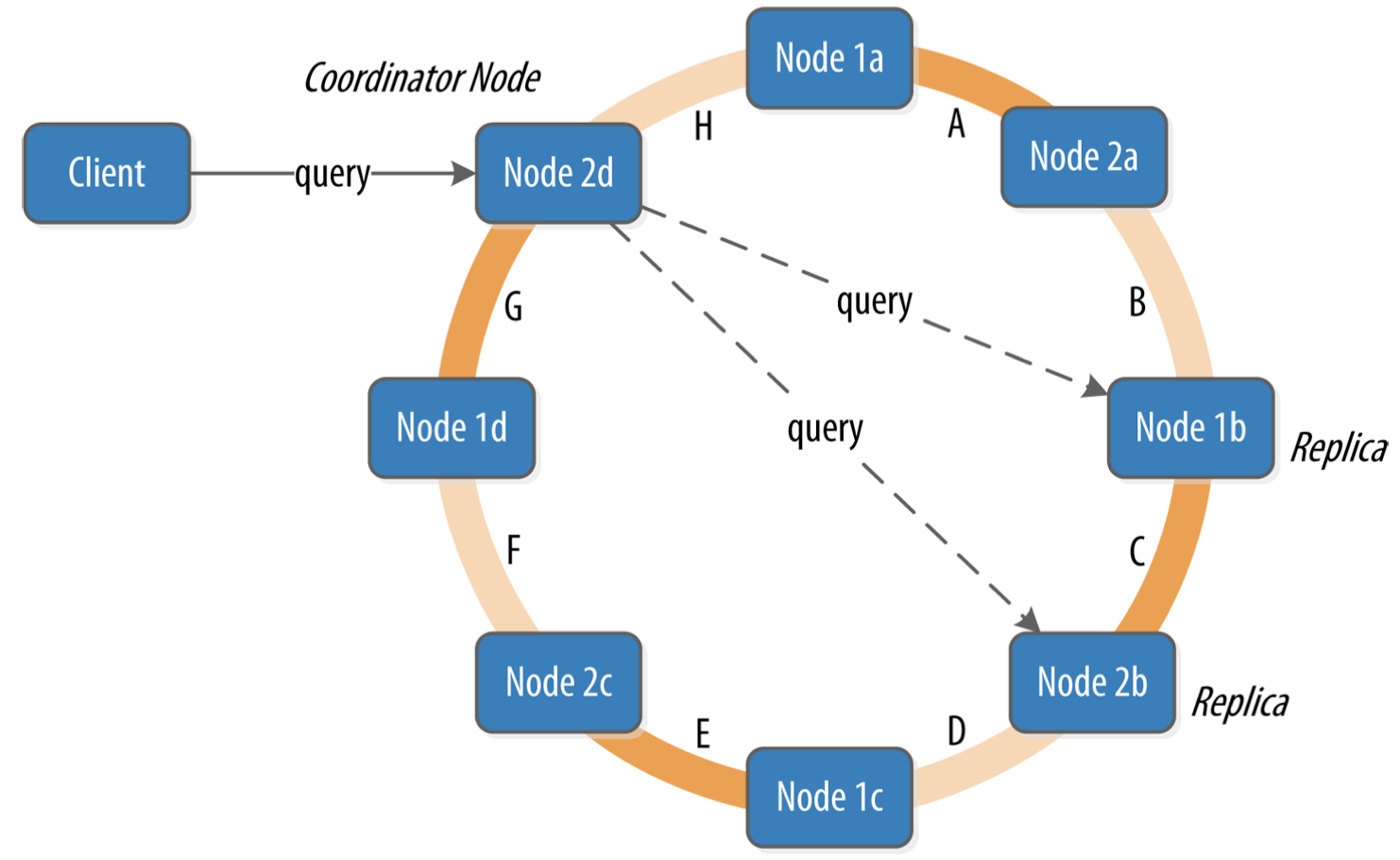
Queries and Coordinator Nodes
客户端可以连接集群中的任一节点作为协调节点,由协调节点执行向副本的读写操作
- 对于写请求,协调节点向所有副本发出写请求,当满足一致性级别数量的副本成功写入后,即回复成功
- 对于读请求,协调节点向满足一致性级别要求数量的副本发送读请求,将数据返回给客户端
由于写入只保证R个节点,其它节点有可能产生不一致的数据。
Cassandra采用 Hinted handoff 提示移交实现写入高可用,repair修复实现数据最终一致性。
Hinted Handoff
写请求发送到协调器后,由于对应的副本故障,无法完成写入。为了保证可用性,Cassandra采用了提示移交的技术。
- 协调节点会创建一个持久化的hint,记录向目标节点的写入事件。
- 一旦目标节点恢复,协调器将hint移交给目标节点完成写入
以此来实现写入的高可用。虽然hint被持久化保存,但此时这些数据是读取不到的,需要等目标节点恢复执行hint中的写操作,才能被读取到。
目标节点恢复后,有可能会涌入大量hint请求,导致节点再次故障,因此Cassandra支持配置限制hint的保留时间,或者禁用hint。
虽然hint提高了系统的可用性,但是仍无法解决数据一致性问题。
Anti-Entropy, Repair and Merkle Tree
反熵协议是Cassandra用来保证数据一致性的协议,是一种用来修复副本数据的gossip协议,通过比较副本数据来修复不一致。
副本同步由两种机制实现:
- 读修复
- 发生在对副本的读操作中,Cassandra从多个副本读取数据并检测是否有副本存在过期数据,如果是则对旧数据进行更新
- 反熵修复
- 使用
nodetool repair手动触发,基于Merkle Tree发现副本的不一致 - Merkle Tree是一种以二叉树表示的hash树,每个叶子节点代表数据块,父节点代表它子节点的hash值。
- 通过比较根节点的hash值,就可以比较两颗树是否相同,如果不同,继续向下继续比较hash值,直到找到不同的部分
- Cassandra中每个表都有自己的Merkle Tree,在反熵修复开始时创建
- 使用
Lighweight Transactions and Paxos
Cassandra提供了可调一致性级别,可以支持到强一致性。但是这种强一致性并不能阻止在客户端发生并发读后写操作时的竞态条件。
对于创建新帐户的请求,需要先读取检查记录是否存在,再进行写入。此时需要的是线性一致性,保证在读写操作期间不会有其它客户端操作这个记录。
Cassandra支持轻量级事务机制,提供了线性一致性保证。它扩展了Paxos共识协议提供了CAS操作来提供轻量级事务。
- 一个成功的LWT轻量级事务需要在协调节点和副本之间完成4个roud-trips,因此比普通的写请求成本更高。
- LWT仅用于对单个partition的操作。
Memtables, SSTables and Commit Logs
Cassandra将数据同时存在内存和磁盘,以提供高性能和持久性,使用memtables,SSTable和commit logs支持从表中读写数据。
节点收到写请求后,首先将数据写入commit log,只有写入commit log后,本次写请求才算处理成功。
- commit log是一种故障恢复机制,实现Cassandra的持久性
- 如果节点关闭或崩溃,commit log能保证数据不丢失。当节点下次启动时,将会
replay这些commit log,此时是唯一读取commit log的情景,客户端不会读取commit log
|
|
写入commit log后,值会被写入内存数据结构memtable。每个memtable包含特定table的数据。
- 当memtable里的对象数超出阈值后,memtable的内容会被
flush到磁盘上的 SSTable中,然后创建一个新的memtable - flush操作时非阻塞的;一个表可能存在多个memtable,一个正在使用,其它的等待被flush到磁盘。
SSTable概念来自Google Bigtable,是Sorted String Table的缩写。Cassandra并不以字符串的形式存储数据,只是借用了SSTable的名词。 可以使用nodetool flush手动触发flush操作
commit log中为每个table分配了一个bit位,用来表示是否需要flush。
- 写请求刚收到时,table对应的flag为1,表示还没有flush
- 一旦memtable被flush到磁盘,commit log中相应的flag置为0,对应了commit log就可以删掉了
- commit log有一个可配置的阈值,用来实现滚动记录,覆盖可以删除的数据
一旦memtable被flush到磁盘成为SSTable,就不可修改了。
- 不过,Cassandra支持SSTable的compression压实,用于释放冗余空间
- SSTable包含多个文件:Data,Index和Filter
对于写操作,磁盘上的写入都是顺序追加写入,这也是Cassandra写性能高的原因。 对于读操作,Cassandra会同时读取SSTable和memtable,因为memtable中可能包含了还未flush到SSTable的数据。
Bloom Filter
Bloom过滤器用来加速读请求,用来判断一个元素是否在集合中,可能出现false-positive假阳,但不会出现false-negative假阴。
- Bloom过滤器基于内存中的bit数组实现,增加Bloom过滤器尺寸有利于降低假阳率
- 每个SSTable文件都对应一个Bloom过滤器,在读取SSTable前,先通过Bloom过滤器判断,用于降低对磁盘文件的访问次数
- Bloom过滤器判断元素不存在,就不需要读取SSTable了
Caching
为加速读取,Cassandra提供了可选的缓存功能:
- key cache, default enabled
- row cache
- chunk cache
- couter cache, default enabled
Compaction
SSTable的不可变性,提高了Cassandra的写性能。周期性的compaction压实这些SSTable有利于提高读操作性能,删除过期数据。在压实过程中,SSTable的内容会被合并,并创建新的索引。 新的排序数据和索引会被写入新的SSTable文件(SSTable包含多个文件:Data,Index和Filter)
压实操作可以通过减少seek调用的次数来提高读操作效率
- 如果一个key被频繁修改,很可能修改会被flush到多个SSTable中
- 通过压实操作,将这些修改合并,就不需要去多个SSTable中执行seek调用了
当压实操作执行时,会临时出现一个磁盘IO吞吐尖峰,在新的SSTable生成过程中,磁盘使用量也会增加。
Cassandra支持为每个表指定自己的压缩策略:
- SizeTieredCompactionStrategy(STCS) :默认策略,适合写密集的表
- LeveledCompactionStrategy(LCS):适合读密集的表
- TimeWindowCompactionStrategy(TWCS):适合时间序列或基于日期的数据
Major compaction
Cassandra提供了一个叫Major compaction或full compaction的操作,将多个SSTables合并到一个SSTable。
- 虽然此功能仍然可用,但随着时间的推移,执行主压实的效用已大大降低。
- 事实上,在生产环境中实际上不鼓励使用,因为这往往会限制Cassandra删除过时数据的能力。
Log Structured Merge(LSM) Tree
前面提到的Cassandra的存储引擎的设计,来源于Google Bigtable的论文,论文最初受LSM-Tree论文的启发。
LSM-Tree论文描述了一种数据结构,是对以前在存储设计中占主导地位的B-Trees(in-place update)的改进。该设计的基本思想是
- 数据首先存储在内存中,然后随着时间的推移,使用归并排序算法合并到磁盘上的一个或多个文件。
- 利用了这样的特性:对旋转磁盘的顺序写入比随机访问更快,在现代基于SSD的存储上也同样有效。
Bigtable的论文介绍了下面这一套概念:
- 用于内存存储的memtable和磁盘存储的SSTable
- memtable中数据的初始存储,提供持久性的预写日志,周期性存储排序数据到不可变的SSTables中
- 使用memtable和Bloom过滤器加速读取,作为后台进程的压实操作合并SSTable文件
多种数据库都采用了LSM Tree的结构,如简单的存储引擎 RocksDB/LevelDB,或者分布式数据库Cassandra/HBase。 LSM Tree数据库的优势在于:
- 追加写存储模型带来的写性能提升
- 读操作虽然不快,但也经过了Bloom过滤器和SSTable索引的加速。
Deletion and Tombstone
考虑这样一种情况一个节点宕机或网络不可达,导致错过了数据的删除事件。当节点恢复后,一旦执行repair,节点就会将已删除的数据复原。
为了阻止这种情况的发生,Cassandra引入了墓碑的概念。在执行删除操作时,数据并不是立即被删除,而是使用更新操作在元素位置放一个墓碑,表示数据已被删除。
墓碑不会一直存在,通过为每个table指定gc_grace_seconds可以限制墓碑存在的时间,最终通过GC或compaction操作删除,默认值为10天。
- 提供这个参数的目的,是给故障节点一个恢复时间。如果一个节点故障时间超出这个值,那么该节点应该被替换掉。
Maerialized View
|
|
基于基表重新创建一个新的“表”,可以重新指定partition key和clustering column,用于支撑某些业务的高效查询。
创建物化视图的一些约束项
- AS SELECT column1, column2, … 子句选择其中的列基表要复制到视图中。基表主键列会被包含在内的。
- WHERE column1 IS NOT NULL AND column2 IS NOT NULL … 字句保证了视图的主键列没有空列
- PRIMARY KEY(column1, column2, …) 子句中应该包含基表的所有主键列,再加上至多有一个列,它不能是基本表的主键的一部分,这些主键列顺序并不重要,可自行抉择。
特点:
- 为实现某些业务逻辑的高效查询,在基表基础上扩展物化视图
- 本质上相当于复制了一个新的表,但只能通过基表联动更新
- 基表写入数据时会加锁,影响写效率